



From 12th to 14th April Leszek Gryz, PhD participated in online 18th USENIX Symposium on Networked Systems Design and Implementation (USENIX NSDI ’21). Here is the summary of the papers which got our interest.
1) When Cloud Storage Meets RDMA
This paper is about Pangu – cloud storage system developed by Alibaba. It describes hands on experience with introducing Remote Direct Memory Access (RDMA). RDMA was required to overcome bottlenecks caused by the rapid advancement in storage media causing networking lagging behind. According to the paper the latency of non-Volatile Memory Express (NVMe) disks is in microsecond range and the total throughput can exceed 100Gbps. But the latency of the TCP/IP network stacks can reach milliseconds and the bandwidth per kernel TCP thread is only tens of Gbps. RDMA with entire protocol stack implemented on host NIC is able to provide microsecond latency and 100Gbps per-connection throughput.
However large-scale RDMA deployments struggle with several problems:
a) Priority Flow Control (PFC) deadlocks.
b) PFC pause frame storms (when an end-port is not able to receive any traffic it keeps sending pause frames towards the switch which in turn repeats the process affecting the whole cluster).
c) Head-of-line blocking.
Pangu addresses these problems mainly by:
a) Creating so called podsets which contains limited number of storage nodes and switches. The hardware is planned to match the disk throughput with the network bandwidth. The communication between computing and storage nodes/podsets is performed using TCP protocol. Thus RDMA related problems affect single podset instead of the whole cluster.
b) Using RDMA/TCP Hybrid Service to switch from RDMA to TCP when PFC storm is detected, to let the storm calm down to be able to switch back to RDMA.
If you are planning to work on scalable system using RDMA it worthy to read the paper because it it describes valuable hands on experience.
2) Orion: Google’s Software-Defined Networking Control Plane
Orion is a distributed Software-Defined Networking platform deployed globally in Google’s datacenter and Wide Area networks. It enables intent-based management and control. Intent-based means that administrators or applications express their desired network state and the system tries to reach the state automatically. So there is no need for coding, manually executing individual tasks or modify network’s hardware settings.
When creating such a big SDN there are several issues you have to take care of. Examples of some of them:
1) In SDN control software is separated from physical elements. They all should be within relatively small failure domain. Otherwise failure of control software (i.e. due to power failure) would result in logical failure of physical elements even though those elements are not physically affected by the failure (i.e. switches are powered up and up and running).
2) When handling failures you cannot easily decide which devices are failed, because controller has incomplete information. For example when a controller has no connection with a switch it can mean that physical connection between the controller and the switch is broken or the switch is broken. Orion decides if it is dealing with minor or major failure. It reacts pessimistically in the former case (i.e. assumes switch is failed and reroutes around it) and optimistically in the latter one (i.e. cannot connect to many switches – it assumes that network connections are broken and does not change anything assuming switches are fine).
3) There is a bootstrap problem. The control software needs to be able control the physical hardware while the SDN may not properly set yet.
3) CodedBulk: Inter-Datacenter Bulk Transfers using Network Coding
Network Coding (NC) is a method of increasing throughput of a network by coding messages that are sent over the network.
Consider the example below on figure 1. There are two source nodes 1 and 2 having message A and B respectively. Both the messages need to be transmitted to node 5 and 6. Each link can carry only one message. Thus the central link between nodes 3 and 4 can transmit message A or B. If it transfers message A then node 6 gets both A and B, but node 5 gets A only. The case if symmetric if central links transmits message B.

Figure 1
However, if the nodes can do more computation that simple routing, node 3 can encode sum of A and B. Nodes 5 can compute B by subtracting A from A+B. Symmetrically node 6 can compute A. This is seen on Figure 2.
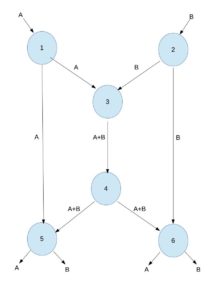
Figure 2
CodedBulk uses Network Coding with hop-by-hop flow control mechanism to speed up bulk transfers of inter-datacenter wide-area network (mostly geo-replications). The throughput is increased by 1.2 − 2.5× compared to state-of-the-art mechanisms that do not use network coding.
4) When to Hedge in Interactive Services
This paper is about improving performance of data-intensive (OLDI) services. Typically a OLDI client request is split into queries which are distributed over many leaf nodes, each holding part (“shard”) of the data required to process the request. If any of the shards delays the reply the latency of the request increases. In big systems with hundreds or thousands leaf nodes such delay hiccups are inevitable and cause increase of tail latency.
To address this problem technique called hedging is used. The shards are replicated. Thus a query to a given shard can be replicated too. Request needs to wait for the fastest response of each replicated query.
However, replication of queries increases load of the system. The naive hedging which, for example, always sends two replicated queries improves latency of non-loaded system, but for heavy loaded system increases the latency because the extra queries increases queuing delay (hedging vs load trade-off).
This paper:
1) Describes a Idealized Hedge – an idealized hedging policy to show what is the most possible gain when using hedging.
2) Then the paper presents Load-Aware Hedge policy which almost as good ad Idealized Hedge and can be implemented in a real system.
5) BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing
Memcached is a distributed memory object caching system.
According to the authors of the paper memcached performance is limited by:
a) Concurrent data structures (e.g. sockets) used by multiple threads.
b) System calls.
c) Per-packet TCP/IP processing.
The paper presents BMC – modified Memcached which serves the requests before the execution of the standard network stack. The “Get” operation is processed between NIC and network stack. The “Set” operation is more or less processed as in original Memcached, but with additional step of updating the state between NIC and network stack.
These improvements increased performance up to 18x.
Note that the approach with processing requests between NIC and the network stack is similar to the ones presented in paper “When Cloud Storage Meets RDMA”.
6) Segcache: a memory-efficient and scalable in-memory key-value cache for small objects
This paper, similarly to “BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing”. It address problem of key-value systems performance. However, it does it from a different perspective.
According to the authors of the paper current solutions has the following problems:
1) Expired entires removed when tired to access => not optimal use of cache, since expired object remain in memory long past expiration.
2) Huge per-object metadata => inefficient memory usage
3) Memory fragmentation.
4) Trade off between memory efficiency and throughput or scalability.
Main features of the proposed solution:
1) Object are stored in segments. Segment is a small fixed-size log storing objects of similar TTLs -> limited memory fragmentation.
2) Segments with similar TTL are grouped together -> efficient proactive TTL expiration.
3) Segment header keeps shared metadata for objects -> object metadata size reduction.
All these features together limit level of locking in the object LRU queues, free object queues, and the hash table which are problems in current solutions like Memcached.
Evaluation shows that:
– Memory footprint is reduced by 22-60% compared to the state of the art.
– Throughput is the same or higher than current solutions (up to 40% higher then Memcached).
– Segcache scales linearly (8x improved with 24 threads).
7) MilliSort and MilliQuery: Large-Scale Data-Intensive Computing in Milliseconds
Typically large scale distributed applications hosted by hundreds servers execute for seconds or minutes. This period of time is necessary to amortize cost of servers coordination and network latencies. But such period of time is inadequate for real-time queries. To overcome this real-time return precomputed results, but it is a limited solution.
However, new serverless platforms such as AWS Lambda, Azure Cloud Functions, and Google Cloud Functions which make it possible to run short-lived as small as function call. It inspired the authors of the paper to question if it is possible to harness large numbers of servers to execute real-time queries in 1 millisecond. After solving problems with coordination, work distribution, network latency (kernel bypass) and per-message overheads it turned out that it is possible.
The authors have implemented two dedicated algorithms: MiliSort (sorting application) and MiliQuery (three sql queries). MilliSort can sort 0.84 million items in one millisecond using 120 servers on an HPC cluster and MilliQuery can process .03–48 million items in one millisecond using 60-280 servers.
8) Ship Compute or Ship Data? Why Not Both?
Typically there are two extreme ways to implement cloud applications interacting with their data:
a) Shipping data from storage servers to application servers (typically using Key-Value storage).
Pros:
– Flexible provisioning.
– Elastic Scaling
Cons:
– Higher network traffic + data marshaling overhead.
– Latency increase due to multiple network round trips for a customer request.
b) Computation shipping to storage severs using RPC calls.
Pros:
– Less network traffic, less marshaling overhead.
– Potentially less network round-trips.
Cons:
– Storage server can get overloaded.
Which strategy is better depends on the proportion of computation and communication.
The paper presents Kayak – system that proactively and automatically adjusts the rate of requests and the fraction of requests to be executed using data shipping or computation shipping.
Evaluation shows that Kayak improves overall throughput by 32.5%-63.4% for compute-intensive workloads and up to 12.2% for non-compute-intensive and transactional work loads over the state-of-the-art. Kayak converges to optimal policy in less than a second.
9) One Protocol to Rule Them All: Wireless Network-on-Chip using Deep Reinforcement Learning
This article deals with the very interesting idea of Wireless Network-on-Chip (NoC). Wireless network is used as communication medium between cores. Such solution significantly reduces the
latency and overhead of multicast and broadcast communication (one package suffices). Also there is a constant time required to pass package between any two cores since there is always one hop. Throughput if such communication is 10-50 Gbps. This allows to build systems with hundreds and thousands of cores.
However, since wireless medium is shared between all cores there needs to be an effective media access (MAC) protocol implemented. It is not easy because:
a) Traffic patterns are very dynamic. They depend on type of application, different type intervals and may be different across cores. The traffic pattern can change within tens of microseconds.
b) MAC has to effectively handle synchronization primitives likes barriers and locks in parallel
programming. For example, if there is N cores and N-1 already waits for last one on the barrier, the last one should get its packages prioritized to limit time of N-1 cores being idle.
The papers presents NeuMAC which uses deep learning to very quickly adopt to changing traffic patterns.
According to evaluation NeuMAC can speed up the execution time by 1.37 × −3.74× as compared to baseline solution.
10) ATP: In-network Aggregation for Multi-tenant Learning and Scaling Distributed Machine Learning with In-Network Aggregation
These two papers address similar problem as 9). In distributed deep neural network training (DT) due to advances in hardware acceleration the performance bottleneck shifted from computation to communication. Both papers describe solution making use of programmable switches to limit the network bottleneck.
The first paper uses programmable switches to aggregate neural network gradients. The second paper proposes usage of programmable switches to aggregate model updates that are passed to workers.