



In cloud computing era distributed storage systems are pervasive. But have you ever thought of how they store data internally? The answer is obviously non-uniform, but let me tell you the adventure we had in designing how the fastest and most scalable deduplicating backup appliance in the world was going to do that.
Why the natural, first choice became a hindrance
When we started building the NEC HydraStor backup appliance as 9LivesData back in 2003, the obvious choice for storing data on disks was to use ext3 — the most popular Linux file system at that time. However, our subsequent struggles in ensuring best performance and storage utilization proved this approach suboptimal. It turned out that a standard POSIX file system might not be the best choice, as it provided a lot of unneeded functionality while not giving us some features which we really wanted. A few examples:
- It was really hard to tell precisely how much data ext3 could still accept, so protection against out of space got tricky. Well, statfs could tell us how many blocks were still available, but guess what? They would be used for indirect blocks as well. So, a single-block append could consume from 1 through 4 blocks on the device, depending on what file we appended to. Not to mention accounting directory size changes on file creation or deletion. Good luck tracking that!
- ext3, like every power failure resistant file system used an internal journal. However, in NEC HydraStor we performed transactions across multiple disks/partitions, so we needed our own, higher-level journal anyway. This resulted in so-called double journaling: every user write issued a metadata update entry in our journal, then on actual write ext3 re-journaled it again and only then the update was finally written to the target location. Yeah, metadata updates are small, you could say, but rewriting even a single 4 KiB block here and there on a rotational drive causes severe latency and bandwidth drops, as the disk head must move a lot.
- We couldn’t tell the user that their data were persistent right after a write call returned. Even opening the file with O_DIRECT flag didn’t guarantee this. To be sure we had to either use O_SYNC flag or issue an fsync call after each write. But this would have increased latency. It’s a pity we couldn’t just tell the user “OK” once the file system had journaled metadata updates and flushed the data, without waiting for applying the journal. However, no API allowed us to skip it.
- We generally wrote large files (multi-megabyte), so ext3’s care about small files hindered us. We didn’t need the partition split into 128 MiB allocation groups to allow for parallel allocation of numerous tiny files. Instead we’d have preferred keeping all data close to the beginning of the drive, as this was placed on the outer edge of HDD plates, which had ca. 2x higher linear speed than the other end.
- When any file system got full, it was challenging to avoid its quick aging. And in case of HydraStor’s workload on nearly full drives, the fragmentation of ext3 skyrocketed.
Other problems included bugs in asynchronous I/O (turning it silently into synchronous), lack of metadata integrity checks, spurious security features in a controlled single-user system and unnecessary directory structures, messing up with performance and requiring additional fsync calls. We also wanted to have the file system supply additional features like on-demand shredding of user data, which is quite hard to achieve otherwise (at least without dirty hacks).
But essentially the most painful problem was the lack of control. We could only guess what was exactly going on beneath the file system interface and we couldn’t directly influence it. How could we implement a good resource manager of block device I/Os in this case? How could we keep track of fragmentation without incurring significant overheads?
Finally we decided to face our fate and push the limits of HydraStor’s performance and manageability by pursuing the most promising approach: replacing ext3 with our own file system layer, IMULA (derived from being optimized for immutable large files). Stay tuned to hear how this happened.
How our expedition began
File systems tend to be large beasts. So, dropping unnecessary items from your backpack (in our case: directories, file names, timestamps, permissions and even precise file sizes) is crucial to succeed with limited budget and timespan. But it’s not enough. You need a good plan.
Our plan started by ensuring that we can successfully defeat the fragmentation issue and squeeze out big bandwidth increases from the underlying hardware. All in all the primary goal was to remove the performance bottleneck from disks, wasn’t it? So, we started by designing the block allocation algorithm.
How would you approach this? Note that a typical workload of HydraStor consisted mostly of:
- large appends to a few open files and
- later rewrites of previously closed files (to optimize them for reads or reclaim unused data chunks), often multiple per file.
First, you want to minimize fragmentation. So let’s allocate whole “extents” instead of single blocks and let’s strive for finding as long extents as possible. Great, but you can do more. You can try to keep subsequent extents close to each other — it will pay off during sequential reads. Interestingly, this is true also between file boundaries, because files written together are typically read together as well (at least in HydraStor). So, let’s leverage the trick of log-structured file systems and try to allocate each new extent right after the last allocated one.
So, with this approach we have two conflicting goals: large extents and extents close to their predecessors. How can both be reached? Let’s just use a few size thresholds to resolve this. Namely, we can first seek the closest extent of size at least 1024 blocks. If this fails, let’s try 256, then 32 and a single block at the end.
But wait! We forgot about an important optimization: keeping data as close to the beginning as possible. So let’s add an additional, first step to this algorithm: seeking the closest extent of 1024 blocks within some initial part of the drive. But what should “initial part” mean?
Imagine that we’d rewritten all data to the very beginning of the partition. Sounds feasible, right? So, why not pick the total occupied space as the “initial part” size? Well, this would bring fragmentation problems of nearly full partitions to that initial part. So, to avoid this, let’s just relax this amount to 120% of total occupied blocks.
Following this reasoning we prepared an allocation algorithm, which looked roughly as follows:
- find the closest extent after the current “allocation pointer” of size at least 1024 blocks, within initial disk part of size = total occupied space * 120%.
- if it fails, try the same within the whole partition.
- then seek the closest free extent within the whole partition, of minimal size 256 blocks, then 32 block and finally 1 block.
- once you’ve found some extent, remember to update the allocation pointer to its end.
That wasn’t not too complex, was it?
Then time for testing came. We tracked bandwidth of a few write patterns with this allocator and a prototypical implementation of user operations in hand. Here’s the chart showing relative comparison between IMULA (blue) and ext3 (red), each running on four HDDs. The graphs are scaled horizontally to the same timespan and have linear vertical scale:
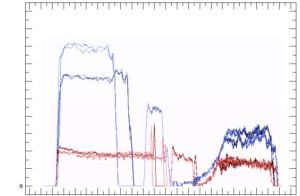 Write bandwidth comparison between IMULA (blue) and ext3 (red) on a write patterns
Write bandwidth comparison between IMULA (blue) and ext3 (red) on a write patterns
As you can see, our first approach was from 2x through 4x times better than ext3. Not bad, huh?
But did it fragment space over time? To check this, we simulated filling the drive to 99% of capacity, then deleting random 5% of data chunks, refilling it back to 99% with new data, deleting 5% again and so on. How was our new shiny idea going to work under such stress? Let’s see:
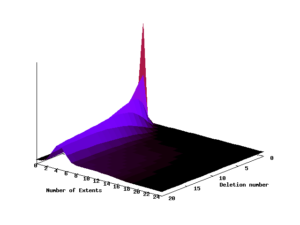
Distribution of the number of extents per file over time (on a nearly full device)
This chart shows how the distribution of the number of extents per file evolved over these 20 rounds of deletion and filling. After 20 cycles our allocation algorithm kept usually around 4 extents per file. This amounted to the mean extent size of 3 MB. Considering the fact that this size was enough to amortize seek times in data access, our first idea proved to work quite well.
As you can see, lots of extensive research to reach sufficient performance with IMULA was not essential.
However, usually when you finish prototyping something and start productizing, many additional efforts pop out on the stage. See what this meant for us.
Filling up the details
OK, so we had a block allocator, what else did we have to implement to have our “file system” up and running?
First, file metadata had to be kept somewhere permanently, so that they could be restored after a power outage. Second, the allocator algorithm needed to keep some map of free extents (which we called a free map). Also, both these structures needed some summary to be kept in a superblock, or rather two superblocks (for robustness against bad sectors and against power outages during updates). So we ended up with the following on-disk layout:
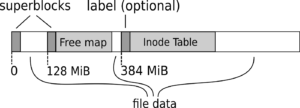
On-disk layout of IMULA
Free map
Ideally, free map could work in memory only (we were hoping for small fragmentation, weren’t we?), but the requirement to support a fast in-place upgrade from ext3 forced us to keep base block size at 4 KiB and be prepared for high initial fragmentation. Luckily, experiments showed that our new shiny allocator decreased high initial fragmentation over time, when fed with HydraStor’s typical workload. That was great news, but still we had to be prepared for an aged file layout and we had to write code evicting metadata to the disk, at least temporarily. So, even despite being able to rebuild the whole free map from sequentially read inode table, we still needed some “Free map file” on disk, at least for swap.
Knowing that we needed “pages” of free map, we divided the disk into “groups”. In order to keep free map file of constant size we decided to save group descriptions as bitmaps of free blocks (just like ext3 and a few other file systems do). This led to a natural group size of 128 MiB — as this is the size corresponding to the number of blocks covered by a single block of bits.
Fine, but note also that direct implementation of our allocator wouldn’t be too fast. We needed a quick operation for finding the closest free extent of some minimal size (within some initial region, falling back to the beginning if none found). Right. Running this on bitmaps could force us to iterate through the whole drive space.
We solved this problem by representing each group by an array of extents starting within it and by building an in-array tree upon these groups, with each node keeping the maximum free extent size within its subtree. Here’s what the typical operation on this tree looked like:
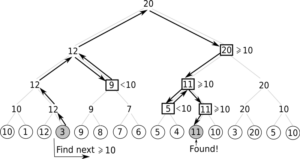
Logarithmic search for the closest next group with a given minimum free extent size
Each circle at the bottom represents the maximum free extent size within one group. Thanks to this approach, each free map traversal required no more than O(log G + g) CPU time (where g was the group size and G — the number of groups) and at most one I/O operation (to fetch a group from disk if needed). Note that we also made our structures quite memory-compact, which helped in keeping as much information in RAM as possible.
Here’s a picture summarizing the design of Free map:

High-level design of Free map
Of course, a diligent reader would instantly spot a few other, minor problems to be solved, including: how extents spanning multiple groups should be handled, what cache eviction strategies should we use or how to optimize traversal of groups containing many free extents. We’ll not tell you in details how we solved each of them, so that you can have more fun tackling it yourself.
Now, let’s come to the next cornerstone of every file system: file metadata.
Inode Table
Well, as I said before, we didn’t need most of the metadata which file systems typically associate with files, like precise sizes (as they were tracked in a different place anyway), paths, directories, names or extended attributes. All we needed was a mapping from a 32-bit file ID to the inode, being a plain list of file’s extents. That was it.
The trick was that the mapping had to be persistent: not only after a clean reboot, but also after a power failure. This was the place where the assumed external journal came to help us.
For resistance against power outages we decided to issue each update in the “ID to extents” mapping immediately to the journal (as a whole new extents list, for simplicity). But in order not to abuse the hospitality of that journal, we avoided keeping enormous amounts of data in it eternally by dumping the updated inodes periodically to the Inode Table file.
The Inode Table file typically had multiple gigabytes on multi-terabyte drives. That was quite a lot to read on startup, so we decided to keep its actual contents in a compact way. We did it by dividing this file into fixed-size buckets and keeping the number of active buckets (that is: the ones we had to read on startup) minimal. Note that this division was not static like in case of Free map — every inode could be kept in any bucket. In fact, it could be kept in a few of them in different versions. By reading buckets in the right sequence we ensured that the most recent inode version was read as the last one. This was the sequence of populating buckets with data and it was stored in Inode Table’s header. Note also that stale versions of inodes, despite being kept in some potentially active buckets, didn’t contribute to their fill.
How could we keep the number of active buckets small? Well.. We had to reuse them whenever possible. So, in common case, when flushing updates from journal we just picked the bucket with the least fill and rewrote its contents together with the new data to a new bucket. To make it possible we only needed to ensure that some bucket was filled to at most half and that one active bucket was empty. This, in turn, could be done by simply setting the desired number of active buckets to a number capable of storing twice the amount of active data plus one. The set of active buckets was adjusted on the fly to the calculated desired number by simply choosing between 0, 1 or 2 buckets to be rewritten together with updates dumped from journal. Quite simple, wasn’t it?
Here’s a chart showing the design of Inode Table. Note the duplicated header (for resiliency against power failure during updating one of them):
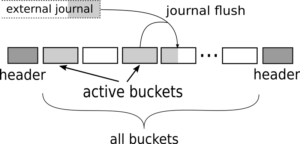
Of course, we didn’t forget about caching inodes in memory. We did it on two LRU lists (for clean and dirty inodes), so that access to them was quick in common case.
An interesting feature of this design was the ability of recovering some consistent (although not necessarily perfectly up to date) state of metadata of all files in case the journal, on which we relied, got corrupt or rewound.
Having reached the goal
We could continue this story with details of a few other nice features, like in-place upgrade from ext3, metadata integrity checksums, dumping all metadata to a tarball for easier support or built-in shredding support by tracking the region of disk to be shredded. Implementing all of this was tremendous fun and has not only increased the performance of our product significantly, but also allowed for easier behavior customization and further performance optimizations due to more control.
Admittedly, a few years after we implemented IMULA, mainstream filesystems like ext4 improved their performance as well and XFS even caught up with our results. However, they involve a lot more complexity and it’d still be quite tricky to tweak them to our workload in comparison to a fully controlled setting of our making. Not to mention implementing custom filesystem-layer features…
This approach has also been used by other systems. One of the most well-known is Ceph, which recently introduced its new storage back end “BlueStore” as a replacement for legacy “FileStore”.
If you, dear reader, also happen to build storage solutions, you might consider implementing your own file system layer as well. As you have seen, it is not as difficult as it may seem and in our case it brought a lot of performance and control improvements. We’d really like to see how it improves your product.
Acknowledgements
IMULA wouldn’t have been implemented so well without Marek Dopiera, Michał Wełnicki, Rafał Wijata, Krzysztof Lichota, Marcin Dobrzycki and Witold Kręcicki, who all contributed to this project, not only me. Great thanks to all of them!
Did you enjoy this article?
If so, go and clap your hands for it on medium: