



“Deleted code is debugged code” [1]. Unfortunately, deletion of code isn’t a suitable solution for most of challenges developers encounter. That’s why the process of software quality assurance must be implemented, even though it is expensive, tiresome and what’s even worse it doesn’t provide any guarantees. Additionally, some developers hate writing tests and maintaining the testing environment (but writing tests is not THAT BAD – according to a survey 31% of devs do enjoy writing unit tests, furthermore 1% prefer writing tests than other code [2]). Anyhow, finding bugs as fast as possible is very important, because a bug discovered at the early stage of development can be even 100 times cheaper to fix than a bug that was found in production [3].
Since computers can perform some tasks faster and more accurately than humans, it is an obviously good idea to delegate some annoying QA tasks to computers. Almost everyone uses simple static code analysis to detect basic code flaws (e.g. checkers in IDE, compiler warnings, pylint). Less often more complicated tools or formal verification is used. Different approach for QA automatization is fuzzing, which is the topic of this article. I spent several months of my life learning about fuzzing and conducting experiments with American Fuzzy Lop (AFL), because it was a subject of my master’s thesis. I defended it and now I want to share my thoughts and results.
What is fuzzing and why should you use it?
Fuzzing is automatic testing achieved by performing a plethora of program executions with different inputs. Generally, the inputs are generated randomly and after each run the program state is verified. If the program crashed (or was in other incorrect state) a bug is reported and the fuzzing can be considered successful.
The idea is very simple, so you can get the impression it can’t work! In further parts of the article I will explain various techniques that improve effectiveness of inputs generation and incorrect state detection. But the truth is, even a simple fuzzer can find fatal bugs in most applications! In 1990 scientists from University of Wisconsin-Madison conducted an experiment [4]. They tested 88 Unix tools like grep, make and vi with a tool that was generating random inputs. Results were surprising – over 25% of tested programs crashed during this experiment! The experiment was repeated in 1995 and the results were very similar [5]. What’s more – some bugs reported in the first experiment weren’t fixed after five years.
In 2004 Michał Zalewski (author of AFL) created mangleme [6] – a generator of broken HTML documents that has around 100 lines of code. This simple script had enough power to find bugs in popular browsers: Internet Explorer [7], Firefox [8], Opera [9] and Lynx [10].
State-of-the-art fuzzers use sophisticated heuristics, binary instrumentation and machine learning to optimize the fuzzing process. AFL detected bugs in hundreds of applications over several years [11]. The trophy list contains software of every type, e.g. media player (VLC), databases (SQLite, BerkeleyDB, MySQL), servers (nginx, Apache httpd), browsers (Safari, Firefox, IE), Adobe Reader and Libre Office.
Given above examples, you can have a feeling that fuzzing is a technique that can find bugs in every piece of software. That’s true, however there are two pitfalls:
- Only some kind of errors can be found using fuzzing.
- In many cases effective fuzzing requires a lot of effort, time and computing power.
What kind of bugs can be found with fuzzing?
Tests generated with fuzzing are classified as negative [12]. That means the application behavior is verified against incorrect data input. Thereupon, you can’t replace unit tests or integration tests with fuzzing. You have to write all the test cases that verifiy that your application works as expected in every normal use-case! Still, the negative test cases are often overlooked by programmers, because it is almost impossible to know and remember every corner case that should be handled in case of a faulty input. That’s why tests generated automatically during fuzzing are so valuable.
Typically the bugs that can be found with negative tests (and therefore fuzzing) are:
- Faulty memory management (especially in C/C++)
- Assertion violations
- Incorrect null handling
- Bad exception handling
- Deadlocks
- Infinite loops
- Undefined behaviors
- Incorrect management of other resources
As mentioned before, during fuzzing the program is executed multiple times and after each execution only a short verification is performed. Problems like deadlocks and infinite loops can be detected easily by setting timeouts. To detect other issues, additional software like AddressSanitizer [13] or UndefinedBehaviorSanitizer [14] can be used.
More specific software issues require additional verification after each program execution. Developers that add many assertions in the code are in a very good situation because fuzzing has an appreciable chance of finding bugs that lead to assertion violation. Other method is to write additional checker for the program output. Full verification of output is rather not possible, but it is enough to verify some approximate result (e.g. the output size or structure). Such a method was used to detect the Heartbleed by Codenomicon [15].
When fuzzing brings benefits?
Typically, fuzzing is used as “software security related” tool. Indeed, most of famous vulnerabilities like Heartbleed, Shellshock or even simple SQL Injection are conducted by providing malformed input that is not handled properly. Definitely fuzzer is an very efficient tool for security hackers. By the way, Michał Zalewski found two post-Shellshock bugs using AFL [15].
What are other great use cases for fuzzing? For most application it is hard to predict if resources utilized on fuzzing will repay or not. The following questions can help you to estimate if the fuzzing will find bugs in your case.
Does your application…
- have sophisticated input format?
- isn’t tested sufficiently?
- can generate loss if not working properly?
- can’t be easily restored after a failure?
- can process multiple inputs per second?
- have inputs of small size (e.g. <100KB)?
- can be accessed by untrusted users?
- behave deterministically for a given input?
- have many code assertions?
The more affirmative answers you gave, the more you should consider fuzzing. For sure it will be much easier to decide if you should start fuzzing after you understand how fuzzing can be done. In next sections I will explain briefly how AFL works and how I conducted extensive fuzzing of a given software.
American Fuzzy Lop
American Fuzzy Lop (AFL) is one of the most popular and successful fuzzers right now. There are different ways it can be used and there are multiple different variations of AFL that allow fuzzing of applications written in different languages, but I will focus on the most common case – fuzzing of application written in C/C++ with the source code that is available (and thus whitebox fuzzing is possible).
The first step is a program compilation with a GCC or CLANG overlay (afl-gcc/afl-clang). In this step additional instrumentation code is added. Instrumentation is used to monitor program behavior during fuzzing – each block of the fuzzed application source code obtains unique identifier. AFL counts each consecutive pair of executed code blocks – as a result AFL can approximate which code blocks were executed as well as order and multiplicity of these executions. Details of the implementation and trade-offs are explained by Michał Zalewski [17]. Moreover, every small nuance can be understood from the source code (AFL is open-source).
Fuzzing process is conducted by running tested application in infinite loop using input files that are generated from previously generated input files using some deterministic and random algorithms. After each execution, the data about program behavior is analyzed – if the program did something new (the counting of code block id pairs gave result that wasn’t seen before) the input file is saved for a future use during fuzzing.
The input generation algorithms are simple and they try to generate inputs using tricks which according to the research [18] have a big chance of cause new program behavior. For example, the input bits are flipped or groups of bytes are overwritten by common values like 0, -1 or 2147483647.
Heartbleed detection example
To give you a better intuition how AFL finds bugs, I will explain what steps AFL did to reproduce Heartbleed within an hour, without any additional knowledge about OpenSSL. The experiment was based on tutorial [19] and you can easily conduct it yourself.
At the very beginning AFL need an initial input file that can be mutated. I started with a text file with 12341234123412 inside, so the fuzzer needs to discover the OpenSSL request format automatically.
After the fuzzing process was started, AFL shortened the input file content to 123412, because AFL realised that such input result in exactly the same program behavior, but is shorter (therefore better for fuzzing). So, the fuzzing was started with one input file that contains 0x31323331320A.
After 3 minutes a file generated by AFL contained 0x18037F00020164 and caused a crash:
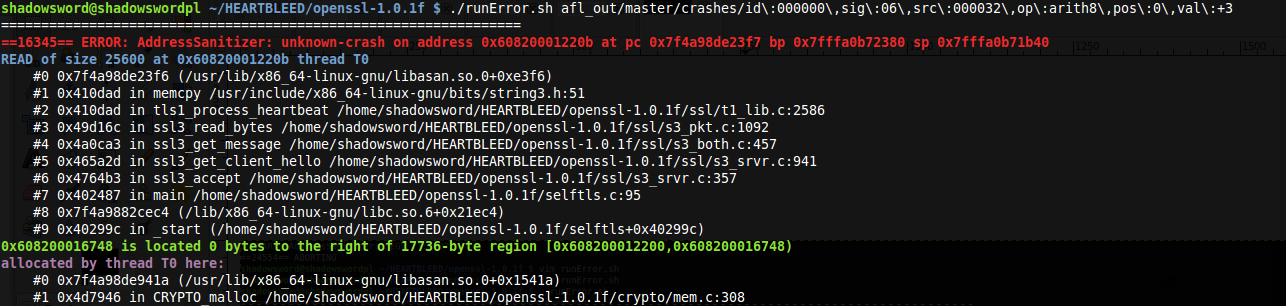
The file contained request of type heartbeat and it cheated the server that the request content is 25600 bytes long. AddressSanitizer crashed because of buffer over-read. AFL detect Heartbleed after 3 minutes of fuzzing!
AFL needed to generate 5 other input files, before the heartbleed reproduction was successful. The path between initial file and
- Ox31323331320A -> Ox35037F0000200A [~1 minute of havoc]
- Ox35037F0000200A -> Ox12037F0002200A [~2 minutes of havoc]
- Ox12037F0002200A -> Ox15037F0002200A [Arith8+3; 18+3 = 21]
- Ox15037F0002200A -> Ox15037F0002010A [Arith8-31; 32 – 31 = 1]
- Ox15037F0002010A -> Ox15037F00020164 [Int100; 100 = 0x64]
- Ox15037F00020164 -> Ox18037F00020164 [Arith8+3; 21 + 3 = 24]
After a first minute of fuzzing, AFL generated input file with new content: 0x35037F0000200A. It was done by havoc mutation that performs multiple modifications on random bytes of input file. It can be seen that the bytes changed after arithmetic operations (31 + 4 = 35) or were changed to a magic constant value (0x03 = 3, 0x7F = 127, 0x00 = 0, 0x20 = 32). The fuzzer decided to save the file with such a content, because instrumentation detected a new program behavior for this file. Similarly 0x12037F0002200A was generated from 0x35037F0000200A after next two minutes.
The remaining 4 steps were done by AFL in few a seconds. When new input file is generated AFL changes each byte of this file using some deterministic mutations before the havoc is started. In this case, Arith8 strategy that adds values from [-35, 35] range to each byte and Int strategy that overwrites values with a magic integer were enough to bring the program to an incorrect state.
During few minutes, AFL was able to generate multiple files that caused several different program executions. As a result, the faulty code with Heartbleed bug was executed and AddressSanitizer that was used along fuzzing caused a program crash. In this example the fuzzing was fast and very successful.
Experiments
In my experiments I had to use fuzzing to test a program that performs a set of actions on images created by backup applications (like EMC NetWorker or Symantec NetBackup). The program implemented 8 different algorithms and each algorithm had to be fuzzed separately. I wasn’t entirely sure if the fuzzing will find any bugs, because the code was tested properly by other tests. Moreover, the backup images in general are big files (bigger than 100MB) while AFL is working the best if the input is shorter than few kilobytes. On the other hand the application was very fast for small inputs (more than 500 execs per second using one core!). I decided to give it a try.
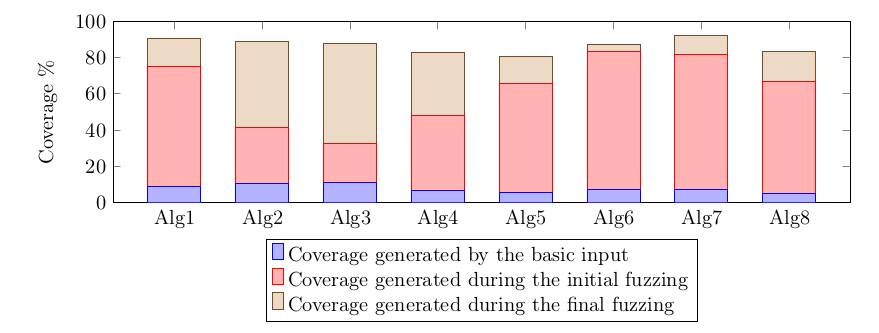
Integration of AFL with my application took some time, because the testing framework was designed to execute the application with two different input files. I had to write an additional layer that generated both files from a single file generated by AFL. Then I started the first experiment – each algorithm was fuzzed with AFL using separate core for 90 hours. No bugs were found, so I decided to measure the fuzzing effectiveness using afl-cov [20] – the tool based on gcov [21] that computes the code coverage generated during fuzzing. The results were very different for each algorithm. The diagram below shows coverage of code generated when input file contained only “basic input” string (blue) and the coverage generated by all input files created by AFL (red):
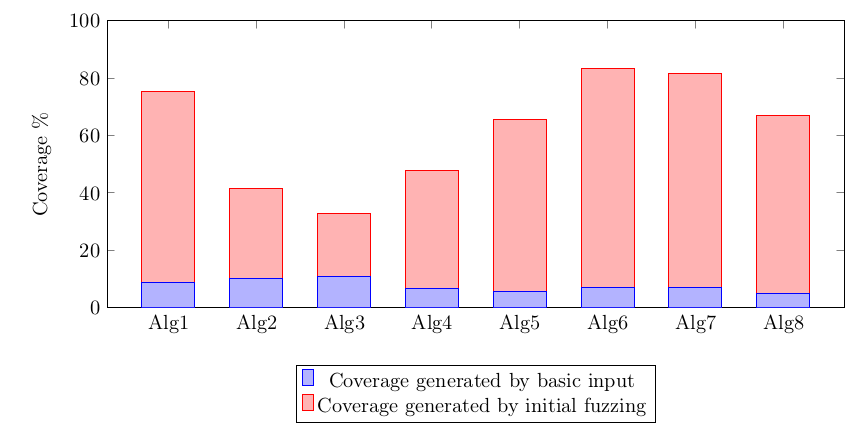
The code coverage that exceeds 80% for two algorithms gave me hope. However, no bugs were found so I decided to analyze the fuzzing to understand how the process can be improved. At the very beginning I understood that waiting longer than 90 hours isn’t a very good idea. After some time AFL the pace of new file generation drastically slows done:
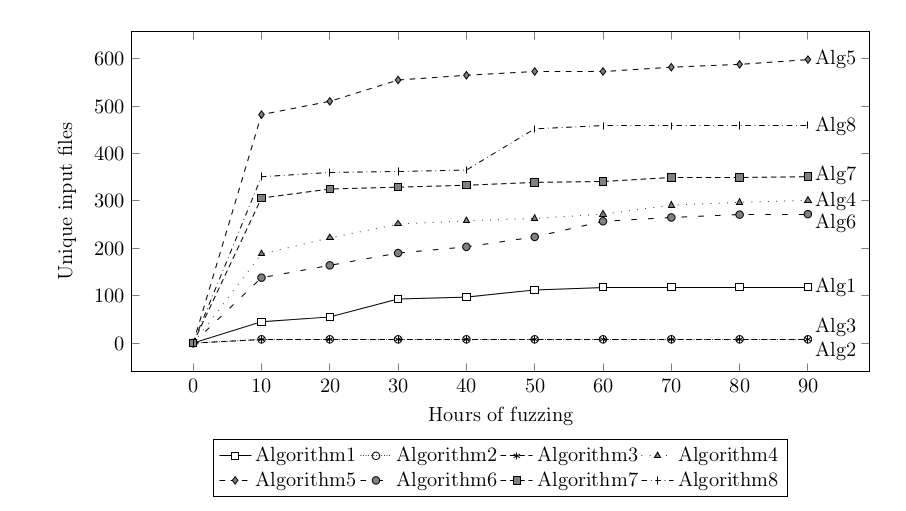
Unfortunately, for algorithms 2 and 3 (with the lowest code coverage) only a few new input files were generated during the first few minutes of fuzzing.
I studied the AFL documentation and source code to understand fuzzing with all details (among others how bytes are mutated, how instrumentation detects new program behaviour and how synchronization works during parallel fuzzing). I used that knowledge to analyze not covered code and find a way to help AFL in covering that code. After several iterations of fuzzing and analyzing I made the following improvements:
- I created dictionaries [22] of constants that were expected to be found in input files but too long to be generated randomly. Each algorithm got separate dictionary.
- I found and reported [23] an issue with dictionary fuzzing that is now fixed from AFL 2.40b
- I added a heuristic that skips deterministic fuzzing for some files bigger than 50KB to my AFL fork (up to 8x speed-up).
- I changed the synchronization mechanism of parallel fuzzing to avoid an issue that results in suboptimal deterministic fuzzing [24]. My solution works efficiently only when fuzzing is performed on a single machine, so it cannot be used in general AFL release.
- I increased granularity of tasks in parallel fuzzing.
- I did some changes in fuzzed application as well – changed some configuration values, disabled an input checksum verification etc.
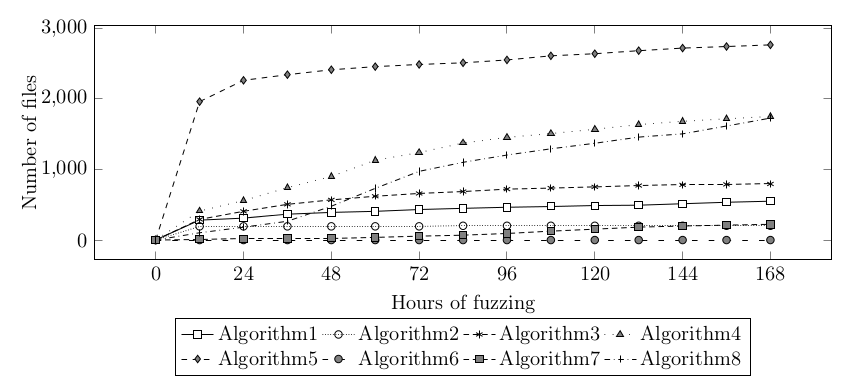
The final fuzzing took one week and each algorithm was fuzzed using one 12-core machine. Code coverage for each algorithm exceeded 80%:
The number of bugs reported by AFL was high, so I needed to write a special classifier, because I wasn’t able to analyze these bugs myself.
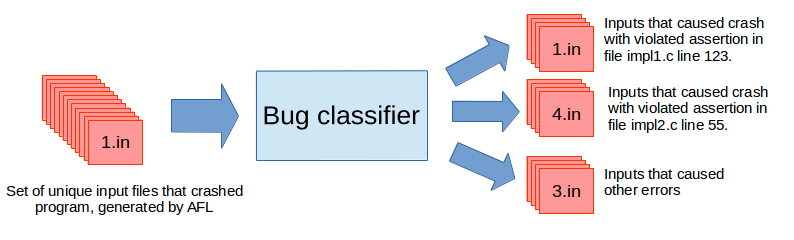
After the classification I got over a dozen of different crash reasons. Most of them were caused by too strong debug assertions, but I found two real bugs as well. Moreover, I was able to repeat fuzzing easily and I found that the fix for one of the bugs didn’t cover all the cases.
Summary
AFL is a very powerful tool. If you put enough effort into fuzzing you can automatically generate very high coverage of your code. Additionally have good mechanism to verify the program state (in my case the code had a lot of assertions) you can detect numerous bugs. You can decide if fuzzing of a particular part of code has a chance to succeed and how much effort you want to put in fuzzing it. If you give it a try you have a chance to detect dangerous bugs that are difficult to find with other methods.
About the author
Andrzej Jackowski is a team leader on the HYDRAstor project at 9LivesData. He graduated from University of Warsaw with a Master’s degree in Computer Science.
References
[1] http://www.defprogramming.com/quotes-by/jeff-sickel/
[2] https://blog.hubstaff.com/survey-many-developers-write-unit-tests/
[3] http://blog.celerity.com/the-true-cost-of-a-software-bug
[4] B. P. Miller, L. Fredriksen, and B. So, “An empirical study of the reliability of unix utilities”, Communications of the ACM, vol. 33, no. 12, pp. 32–44, 1990.
[5] B. P. Miller, D. Koski, C. P. Lee, V. Maganty, R. Murthy, A. Natarajan, and J.Steidl, “Fuzz revisited: A re-examination of the reliability of unix utilities and services”, Technical Report CS-TR-1995-1268, University of Wisconsin, Tech. Rep., 1995.
[6] http://lcamtuf.coredump.cx/soft/mangleme.tgz
[7] https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2004-1050
[8] https://bugzilla.mozilla.org/show_bug.cgi?id=264944
[9] https://www.cvedetails.com/cve/CVE-2004-1615/
[10] http://securitytracker.com/id?1011809
[11] http://lcamtuf.coredump.cx/afl/
[12] https://en.wikipedia.org/wiki/Negative_Testing
[13] https://clang.llvm.org/docs/AddressSanitizer.html
[14] https://clang.llvm.org/docs/UndefinedBehaviorSanitizer.html
[15] https://www.dwheeler.com/essays/heartbleed.html#fuzzer-examine-output
[16] https://www.itnews.com.au/news/further-flaws-render-shellshock-patch-ineffective-396256
[17] http://lcamtuf.coredump.cx/afl/technical_details.txt
[18] https://lcamtuf.blogspot.com/2014/08/binary-fuzzing-strategies-what-works.html
[19] https://blog.hboeck.de/archives/868-How-Heartbleed-couldve-been-found.html
[20] https://github.com/mrash/afl-cov
[21] https://gcc.gnu.org/onlinedocs/gcc-5.3.0/gcc/Gcov.html
[22] https://github.com/rc0r/afl-fuzz/tree/master/dictionaries
[23] https://groups.google.com/forum/#!topic/afl-users/xH1l–B-haw
[24] https://groups.google.com/forum/#!topic/afl-users/DjsYfpCZS1s